
ROC曲线分析
| 命令: | 统计 |
什么是ROC曲线?
ROC 曲线是参数不同截止点的真阳性率(灵敏度)与假阳性率(100-特异性)的函数关系图。ROC 曲线上的每个点代表对应于特定决策阈值的灵敏度/特异性对。ROC 曲线下面积 (AUC) 是衡量参数区分两个诊断组(患病/正常)的程度的指标。
MedCalc 可创建完整的敏感性/特异性报告。
ROC曲线是诊断性试验评估的基本工具。
理论总结
使用受试者工作特征 (ROC) 曲线分析评估测试的诊断性能或区分患病病例和正常病例的测试的准确性(Metz,1978;茨威格和坎贝尔,1993)。ROC曲线还可用于比较两个或多个实验室或诊断测试的诊断性能(Griner等人,1981)。
当您考虑两个人群中特定测试的结果时,一个人群患有疾病,另一个人群没有疾病,您很少会观察到两组之间的完美分离。实际上,测试结果的分布会重叠,如下图所示。

对于您选择区分两个人群的每个可能的临界点或标准值,将有一些病例将该疾病正确分类为阳性(TP = 真阳性分数),但某些病例将该疾病归类为阴性(FN = 假阴性分数)。另一方面,一些没有疾病的病例将被正确归类为阴性(TN = 真阴性分数),但一些没有疾病的病例将被归类为阳性(FP = 假阳性分数)。
测试的示意图结果
下表表示了不同的馏分(TP、FP、TN、FN)。
| 疾病 | |||||||
| 测试 | 存在 | n | 不存在 | n | 总 | ||
| 阳性 | 真阳性 (TP) | a | 假阳性 (FP) | c | a + c | ||
| 阴性 | 假阴性 (FN) | b | 真阴性 (TN) | d | b + d | ||
| 总 | a+b | c + d |
可以定义以下统计信息:
| 敏感性 | a/(a+b) | 特异性 | d/(c+d) | |
| 正 似然 比 | Sensitivity/(1 – Specificity) | 负 似然 比 | (1 – Sensitivity)/Specificity | |
| 阳性 预测 值 | a/(a+c) | 阴 性预测 值 | d/(b+d) |
- 敏感性(Sensitivity):当疾病存在时检测结果呈阳性的概率(真阳性率,以百分比表示)。 Sensitivity=a/(a+b)
- 特异性(Specificity):当疾病不存在时,检测结果为阴性的概率(真阴性率,以百分比表示)。Specificity=d/(c+d)
- 阳性似然比:在疾病存在的情况下检测结果呈阳性的概率与在不存在疾病的情况下检测结果呈阳性的概率之间的比率,即+LR=True positive rate/False positive rate=Sensitivity/(1−Specificity)
- 阴性似然比:在疾病存在的情况下检测结果为阴性的概率与在不存在疾病的情况下检测结果为阴性的概率之间的比率,即−LR=False negative rate/True negative rate=(1−Sensitivity)/Specificity
- 阳性预测值:当检测结果呈阳性时,疾病存在的概率(以百分比表示)。PPV=a/(a+c)
- 阴性预测值:当检测结果为阴性时,疾病不存在的概率(以百分比表示)。NPV=d/(b+d)
敏感性和特异性与标准值
当您选择更高的标准值时,假阳性分数将随着特异性的增加而降低,但另一方面,真阳性分数和灵敏度将降低:

当您选择较低的阈值时,真阳性分数和灵敏度将增加。另一方面,假阳性分数也会增加,因此真阴性分数和特异性会降低。
ROC曲线
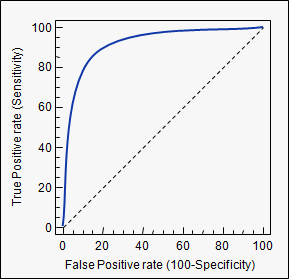
在受试者工作特征 (ROC) 曲线中,真阳性率(灵敏度)绘制为不同截止点的假阳性率(100-特异性)的函数。ROC 曲线上的每个点代表对应于特定决策阈值的灵敏度/特异性对。具有完美区分(两个分布没有重叠)的测试具有穿过左上角的 ROC 曲线(100% 灵敏度,100% 特异性)。因此,ROC曲线越靠近左上角,测试的整体精度就越高(Zweig&Campbell,1993)。
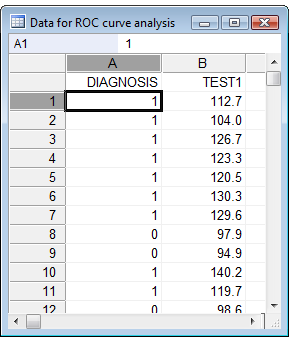
如何输入用于 ROC 曲线分析的数据
为了在 MedCalc 中进行 ROC 曲线分析,您应该有一个感兴趣的测量值(= 您要研究的参数)和一个独立的诊断,将您的研究对象分为两个不同的组:患病组和非患病组。后一种诊断应独立于感兴趣的测量。
在电子表格中,为感兴趣的变量创建一个列 DIAGNOSIS 和一个列,例如 TEST1。对于每个研究对象,输入诊断代码如下:1 表示患病病例,0 表示非患病或正常病例。在 TEST1 列中,输入感兴趣的测量值(可以是测量值、等级等 – 如果数据是分类的,请使用数值对其进行编码)。
所需输入
完成 ROC 曲线分析对话框,如下所示:

数据
- 变量:选择感兴趣的变量。
- 分类变量:选择或输入指示诊断的二分类变量(0 = 阴性,1 = 阳性)。如果数据的编码方式不同,则可以使用定义状态工具对数据进行重新编码。
- 过滤器:(可选)过滤器,以便仅包含选定的案例子组(例如 AGE>21,=“Male”)。
方法论
- DeLong等人:使用DeLong等人(1988)的方法计算曲线下面积的标准误差(推荐)。
- Hanley & McNeil:使用Hanley & McNeil(1982)的方法计算曲线下面积的标准误差。
- AUC 的二项式精确置信区间:计算曲线下面积的精确二项式置信区间(推荐)。如果未选择此选项,则置信区间的计算方式为 AUC ±其标准误差的 1.96。
疾病患病率
虽然敏感性和特异性以及 ROC 曲线以及阳性和阴性似然比与疾病患病率无关,但阳性和阴性预测值高度依赖于疾病患病率或疾病的既往概率。因此,当疾病患病率未知时,程序无法计算阳性和阴性预测值。
临床上,疾病患病率与进行测试前出现疾病的概率相同(先前患病的概率)。
- 未知:当疾病患病率未知或与当前统计分析无关时,请选择此选项。
- 阳性组和阴性组的病例比率反映了疾病的患病率:如果阳性组和阴性组的样本量反映了该疾病在人群中的实际患病率,则可以通过选择此选项来指示。
- 其他值 (%):或者,您可以输入疾病患病率的值,以百分比表示。
选项
- 列出具有测试特征的标准值:用于创建与 ROC 曲线坐标相对应的标准值列表的选项,以及相关的敏感性、特异性、似然比和预测值(如果疾病患病率已知)。
- 包括所有观察到的标准值:选择此选项时,程序将列出所有可能的阈值的敏感性和特异性。如果未选择此选项,则程序将仅列出 ROC 曲线中更重要的点:对于相同的灵敏度/特异性,它将给出具有最高特异性/灵敏度的阈值(标准值)。
- 灵敏度/特异性、似然比和预测值的 95% 置信区间:选择所需的置信区间。
- 考虑成本计算最佳标准值:考虑疾病患病率和假阳性和阴性决策的成本来计算最佳标准值的选项(Zweig & Campbell,1993)。仅当疾病流行率已知时,此选项才可用(见上文)。
- FPc:假阳性决策的成本。
- FNc:假阴性决策的成本。
- TPc:真阳性决策的成本。
- TNc:真阴性决策的成本。
- FPc 不能等于 TNc
- FNc 不能等于 TPc
- 当 TNc 大于 FPc 时,TPc 必须大于 FNc
- 当 TNc 小于 FPc 时,TPc 必须小于 FNc
- 高级:单击此按钮可查看一些高级选项:这些选项需要bootstrapping,并且计算密集且耗时。
- 在固定特异性和敏感性下估计敏感性和特异性:编制一个估计敏感性和特异性的表格,BCa自举的95%置信区间(Efron,1987;Efron&Tibshirani,1993),固定和预先指定的特异性和敏感性为80%,90%,95%和97.5%(周等人,2002)。
- Bootstrap Youden 指数置信区间:计算 Youden 指数及其相关条件值的 BCa 自举 95% 置信区间。
- Bootstrap 复制:输入 Bootstrap 复制数。1000 次重复是文献中常见的数字。高数字不仅提高了准确性,但也增加了处理时间。
- 随机数种子:这是随机数生成器的种子。输入 0 作为随机种子;当重复该过程时,这可能会导致不同的置信区间。任何其他值都将给出一个可重复的“随机”序列,这将导致置信区间的可重复值。
ROC图
- 选择“显示 ROC 曲线窗口”以在单独的窗口中获取图形。选项:
- 标记与标准值相对应的点。
- 显示 ROC 曲线的 95% 置信边界 (Hilgers, 1991)。
结果
样本量
首先,程序显示两组中的观测值数量。关于样本量,有人建议从总共约100次观察的ROC实验中得出有意义的定性结论(Metz,1978)。

ROC 曲线下面积,具有标准误差和 95% 置信区间

这个值可以解释如下(周,Obuchowski和McClish,2002):
- 所有可能的特异性值的平均敏感性值;
- 所有可能的敏感性值的平均特异性值;
- 从阳性组中随机选择的个体的测试结果比从阴性组中随机选择的个体具有更大的怀疑的概率。
当所研究的变量无法区分两组时,即两个分布之间没有差异,面积将等于 0.5(ROC 曲线将与对角线重合)。当两组的值完全分离时,即分布没有重叠,ROC 曲线下的面积等于 1(ROC 曲线将到达图的左上角)。
95% 置信区间是 ROC 曲线下的真实(总体)面积具有 95% 置信度的区间。
显著性水平或 P 值是找到观察到的样本 ROC 曲线下的面积的概率,而实际上 ROC 曲线下的真实(总体)面积为 0.5(原假设:面积 = 0.5)。如果 P 很小 (P<0.05),那么可以得出结论,ROC 曲线下的面积与 0.5 显著不同,因此有证据表明实验室测试确实具有区分两组的能力(Hanley & McNeil,1982;茨威格和坎贝尔,1993)。
Youden 索引

Youden 指数 J (Youden, 1950) 定义为:
J=max {sensitivityc+specificityc−1}
其中 c 范围超过所有可能的条件值。
从图形上看,J 是 ROC 曲线与对角线之间的最大垂直距离。
只有当疾病患病率为50%,敏感性和特异性同等重要,各种决策的成本被忽略时,与Youden指数J对应的标准值才是最优标准值。
当选择了相应的高级选项时,MedCalc 将计算 BCa自举的 95% 置信区间(Efron,1987;Efron&Tibshirani,1993)的Youden指数及其相应的标准值。
标准值
MedCalc 不仅报告阈值或标准值,还报告带有比较符号的标准值,>或≤,具体取决于较高值是否表示疾病,或者较低值表示疾病。
请参阅有关标准值的注释。
最优准则
仅当已知疾病患病率和成本参数时,才会显示此面板。

最佳标准值不仅考虑了敏感性和特异性,还考虑了疾病患病率和各种决策的成本。当这些数据已知时,MedCalc 将计算最佳标准以及相关的敏感性和特异性。当选择了相应的高级选项时,MedCalc 将计算 BCa自举的 95% 置信区间(Efron,1987;Efron和Tibshirani,1993)用于这些参数。
当测试用于筛查或排除诊断可能性时,可以选择具有更高灵敏度的临界值;当使用检测来确认疾病时,可能需要更高的特异性。
汇总表
仅当选择了相应的“高级”选项时,才会显示此面板。

汇总表显示了80、90、95和97.5%的固定和预先指定的敏感性的估计特异性,以及固定和预先指定的特异性的估计敏感性(周等人,2002),以及相应的标准值。
置信区间是 BCa 自举的 95% 置信区间(Efron, 1987;Efron和Tibshirani,1993)。
ROC 曲线的标准值和坐标

结果窗口的这一部分列出了不同的过滤器或临界值及其相应的测试灵敏度和特异性,以及阳性 (+LR) 和阴性似然比 (-LR)。当疾病患病率已知时,程序还将报告阳性预测值 (+PV) 和阴性预测值 (-PV)。
当您未选择“包括所有观察到的标准值”选项时,程序仅列出 ROC 曲线中更重要的点:对于相同的灵敏度(或特异性),它给出具有最高特异性(或灵敏度)的阈值(标准值)。当您选择“包括所有观察到的标准值”选项时,程序将列出所有可能的阈值的灵敏度和特异性。
- 灵敏度(可选 95% 置信区间):存在疾病时检测结果呈阳性的概率(真阳性率)。
- 特异性(可选 95% 置信区间):当疾病不存在时检测结果为阴性的概率(真阴性率)。
- 阳性似然比(可选 95% 置信区间):在存在疾病的情况下检测结果呈阳性的概率与在不存在疾病的情况下检测结果呈阳性的概率之间的比率。
- 阴性似然比(可选 95% 置信区间):在存在疾病的情况下检测结果为阴性的概率与在不存在疾病的情况下检测结果为阴性的概率之间的比率。
- 阳性预测值(可选 95% 置信区间):检测结果呈阳性时出现疾病的概率。
- 阴性预测值(可选 95% 置信区间):检测阴性时不存在疾病的概率。
- 成本*:在该决策级别使用诊断测试所产生的平均成本。请注意,此处报告的成本不包括“间接成本”,即执行测试的成本,该成本在所有决策级别都是恒定的。 *仅当疾病患病率和成本参数已知时,才会显示此列。
敏感性、特异性、阳性和阴性预测值以及疾病患病率以百分比表示。
敏感性和特异性的置信区间是“精确的”Clopper-Pearson置信区间。
似然比的置信区间是使用 Altman 等人 2000 年第 109 页给出的“对数法”计算的。
预测值的置信区间是 Mercaldo 等人 2007 年给出的标准 logit 置信区间。
ROC曲线
当您在对话框中选择相应的选项时,ROC 曲线将显示在第二个窗口中。

在 ROC 曲线中,真阳性率(灵敏度)绘制为不同临界点的假阳性率(100-特异性)的函数。ROC 曲线上的每个点代表对应于特定决策阈值的灵敏度/特异性对。具有完美区分(两个分布没有重叠)的测试具有穿过左上角的 ROC 曲线(100% 灵敏度,100% 特异性)。因此,ROC曲线越靠近左上角,测试的整体精度就越高(Zweig&Campbell,1993)。
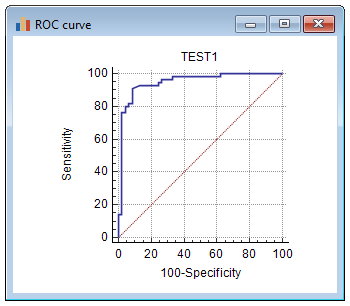
当您单击 ROC 曲线的特定点时,将显示具有灵敏度和特异性的相应截止点。

这是带有选项包括 95% 置信边界的 ROC 曲线:
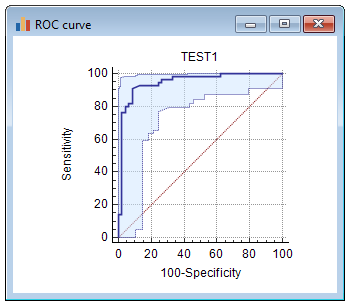
结果介绍
在不同的临床环境中,疾病的患病率可能不同。例如,当患者咨询专科医生时,阳性检测的预检概率会高于咨询全科医生时。由于阳性和阴性预测值对疾病的患病率很敏感,因此比较来自疾病患病率不同的不同研究的这些值,或将它们应用于不同的环境中,可能会产生误导。
结果窗口中的数据可以汇总到一个表格中。应明确说明两组的样本量。该表可以包含不同标准值、相应的敏感性(95% CI)、特异性(95% CI)以及可能的阳性和阴性预测值的列。该表不仅应包含单个临界值的测试特征,而且最好应有一行对应于灵敏度为 90%、95% 和 97.5%,特异性为 90%、95% 和 97.5%,以及对应于 Youden 指数或最高准确度的值。
有了这些数据,任何读者都可以通过以下基于贝叶斯定理的公式计算出适用于他自己的临床环境的阴性和阳性预测值,当知道在这种情况下疾病的先验概率(测试前概率或疾病患病率)时:
PPV=(sensitivity×prevalence)/(sensitivity×prevalence+(1−specificity)×(1−prevalence))
和
NPV=(specificity×(1−prevalence))/((1−sensitivity)×prevalence+specificity×(1−prevalence))
负似然比和正似然比必须谨慎处理,因为它们很容易被误解。
文献
- DeLong ER, DeLong DM, Clarke-Pearson DL (1988) 比较两条或多条相关受试者工作特征曲线下的面积:一种非参数方法。生物识别技术 44:837-845。
- Efron B (1987) 更好的 Bootstrap 置信区间。美国统计协会杂志 82:171-185。
- Efron B, Tibshirani RJ (1993) 引导简介。查普曼和霍尔/CRC。
- Greiner M, Pfeiffer D, Smith RD (2000) 诊断测试中受试者工作特征分析的原理和实际应用。预防兽医学 45:23-41。
- Griner PF, Mayewski RJ, Mushlin AI, Greenland P (1981) 诊断测试和程序的选择和解释。内科年鉴 94:555-600。
- Hanley JA, Hajian-Tilaki KO (1997) 受试者工作特征曲线下面积的非参数估计的抽样变异性:更新。学术放射学 4:49-58。
- Hanley JA, McNeil BJ (1982) 受试者工作特征 (ROC) 曲线下面积的含义和用途。放射学 143:29-36。
- Hilgers RA (1991) ROC 曲线的无分布置信边界。医学信息方法 30:96-101。
- Mercaldo ND, Lau KF, 周 XH (2007) 预测值的置信区间,重点是病例对照研究。医学统计 26:2170-2183。
- Metz CE (1978) ROC分析的基本原理。核医学研讨会 8:283-298。
- Youden WJ (1950) 评级诊断测试的索引。巨蟹座 3:32-35。
- 周 XH, Obuchowski NA, McClish DK (2002) 诊断医学中的统计方法。Wiley-Interscience(威利-跨科学)。
- Zweig MH, Campbell G (1993) 受试者工作特征 (ROC) 图:临床医学的基本评估工具。临床化学 39:561-577。
另请参阅
- 样本量计算:ROC曲线下面积
- 交互式点阵图
- 绘图与标准值
- 预测值
- 区间似然比
- ROC曲线的比较(相关ROC曲线,来自相同的案例)
- 独立ROC曲线(亚组ROC曲线)的比较
- 设置图表格式
- 图形图例
- 添加图形对象
- 参考线
外部链接
- 维基百科上的ROC工作特性。